Frontier psychology
https://www.frontiersin.org/journals/physiology/rss
Source Author
1 Introduction
Chronic heart failure (CHF) is a serious manifestation of advanced cardiac diseases, characterized by impaired cardiac function and circulation. Different subtypes of chronic heart failure exhibit distinct clinical manifestations and symptoms. Accurate identification of these subtypes allows for precise diagnosis and tailored treatment based on individual characteristics. Although diagnosing HFpEF is straightforward in acutely decompensated patients, it becomes more challenging in stable euvolemic patients (Reddy et al., 2018). Echocardiography and B-type brain natriuretic peptide (BNP) are commonly used for diagnosis, but they may not be sufficient for HFpEF (Borlaug and Paulus, 2011), where ventricular systolic function remains preserved. This creates a diagnostic challenge, especially for patients with BNP values between 100 and 500 pg/mL (Chen et al., 2021). Non-specialists might not have immediate access to invasive cardiac catheterization for confirming elevated LV filling pressures. Conducting specialist diagnostic tests on every patient is neither practical nor feasible, as it would be time-consuming, expensive, and often unnecessary.
The graphical representation of sounds caused by the heart mechanical movement during each cardiac cycle, known as a phonocardiogram (PCG) can offer a noninvasive, risk-free, and cost-effective diagnostic tool for detecting CHF. Specific patterns and characteristics of heart sounds can assist clinicians in identifying subtypes of CHF and assessing its severity (Luo et al., 2023). For example, certain murmurs, abnormal heart rhythms, or extra heart sounds may be associated with specific subtypes of heart failure, such as systolic or diastolic dysfunction. Changes in heart sounds, such as the disappearance or alteration of specific sounds, can indicate improvements or worsening of the underlying condition (Drazner et al., 2003). Analyzing heart sound (HS) features can provide valuable diagnostic clues and offer insights into the pathophysiological mechanisms of heart failure (Cao et al., 2020). However, it remains unclear whether these distinctive features in heart sounds can aid in the identification of HFpEF.
2 Related studies
2.1 The application of PCG to CHF
In recent years, utilizing PCG as a diagnostic tool for the diagnosis of cardiovascular diseases, particularly CHF, has increased and shown promising results (Gao et al., 2020; Gjoreski et al., 2020). We have investigated a machine learning model that integrates time-domain, time-frequency, and nonlinear features of heart sounds to determine whether the heart is in a state of CHF (Zheng et al., 2015). Thakur et al. (2017) found that PCGs can capture critical acoustic signatures associated with haemodynamic changes, offering valuable information about the pathophysiology of heart failure. Gao et al. (2020) proposed GRU model effectively learns features directly from HS signals without relying on expert knowledge, demonstrating the potential of HS analysis in early HF detection. Gjoreski et al. (2020) proposes a method for detecting CHF based on HS signals, which combines expert feature-driven classical machine learning with end-to-end deep learning models. We extracted multi-scale features from heart sounds and employed machine learning techniques to perform heart failure staging (Zheng et al., 2022). The above research indicates that PCG characteristics for CHF hold promise for early diagnosis, while also enhancing the sensitivity and specificity of diagnostic methods. The significance of diagnosing HFpEF stems from the fact it requires different treatment approaches compared to heart failure with reduced ejection fraction (HFrEF). Therefore, it highlights the necessity of accurately classifying and diagnosing the subtypes of heart failure. However, because of the complexity and heterogeneity of HFpEF, existing studies contain fewer reports on the HS analysis for the diagnosis of HFpEF, compared with those assessing the presence of heart failure, with little research into heart failure subtype recognition.
2.2 Transfer learning and ensemble learning methods
The success of PCG classification relies heavily on the feature extraction phase in machine learning. Typically, segmentation points of the PCG are used to extract time-domain features as a standard method (Tang et al., 2010), and furthermore, incorporating frequency-domain or nonlinear features can enhance the classification performance of the model (Ghosh et al., 2022). The advancement of time-frequency decomposition techniques (Zeng et al., 2021), including wavelet transform, wavelet packet transform, and variational mode decomposition, has enhanced the feature extraction of PCG signals, and it is possible to explore detailed information from time and frequency domains at different scales. The feature extraction across multiple domains including the time, frequency, time-frequency or nonlinear domains, coupled with multiscale integration of these features, currently represents the most widely adopted approach (Bao et al., 2023; Khan et al., 2020; Fakhry and Gallardo-Antolín, 2024). The accuracy of classification in these traditional approaches is heavily influenced by both the type and quantity of extracted features, as well as the complexity of the classifier design specific to the pattern recognition challenge.
While end-to-end deep learning has demonstrated outstanding performance across various domains by automatically extracting features from PCG spectrograms and eliminating the manual feature extraction step (Ren et al., 2022), it often requires an extensive volume of training data to mitigate overfitting. However, these models exhibit limited generalization capabilities when trained on small datasets, and access to specialized CHF databases containing a wide variety of heart sounds remains restricted. Recently, transfer learning has emerged as a pivotal solution for small-sample classification, enabling the community to address increasingly complex challenges with continuously improving accuracy. Utilizing transfer learning for feature extraction from PCG spectrograms offers a potential solution to enhance HS classification results in small databases (Khan et al., 2021). The extracted feature vectors are then fed into classifiers such as support vector machine (SVM), random forests (RF), convolutional neural networks (CNNs) and long short-term memory networks (LSTM) (Xiao et al., 2020; Zheng et al., 2023), which also has shown significant improvements in classification.
3 Proposed methods
Given the limited sample size of HFpEF heart sound data, this study employs machine learning for model construction. Leveraging the advantages of transfer learning in small-sample tasks, this study intends to utilize pre-trained CNNs for feature extraction, thereby significantly reduces dependence on handcrafted feature engineering processes. Consequently, one-dimensional PCG signals are converted into two-dimensional spectrograms. Considering that texture analysis provides valuable insights for quantitative image feature characterization, we propose an ensemble learning framework that effectively combines transfer learning and texture analysis models through a stacking heterogeneous ensemble mechanism to discriminate HFpEF. Furthermore, a weighted-based heterogeneous stacking ensemble mechanism is introduced to optimize model integration strategies. The ensemble model integrats the individual classification results of base learners according to a weighted AUC-based integration mechanism, resulting in a fused classification output. The workflow of this study is illustrated in Figure 1A. The proposed model’s effectiveness is further assessed against that of the individual models and baseline models on same database. Thus, the major contributions of this study are as follows:
1. This study proposes a heterogeneous stacking ensemble learning approach based on a weighted AUC-based integration mechanism, and for the first time explores the use of PCG-based ensemble learning for the diagnosis of HFpEF.
2. This study investigates the novel application of texture analysis for feature extraction from PCG spectrograms, effectively integrating both textural and deep features to advance HFpEF diagnosis. This study is also the first to apply texture analysis for heart sound feature extraction.
3. This study validates texture analysis as an effective approach for extracting higher-order statistical features from PCG spectrograms. Furthermore, we demonstrate the efficacy of the proposed ensemble strategy in enhancing comprehensive diagnostic performance through comparative experiments.
4 Materials and methods
4.1 Datasets
The proposed method was evaluated using two datasets inclluding the public PhysioNet/CinC 2016 open-source database and a private clinical dataset comprising heart failure cases collected at our hospital between March and December 2023. A detailed summary of the heart failure PCG dataset and the PhysioNet/CinC 2016 dataset is presented in Tables 1, 2, respectively. This study received approval from our hospital’s Medical Ethics Committee (approval number 2022-228), and all participants gave written consent. The diagnosis of HFpEF was made by experienced physicians according to expert guidelines. All patients rested for 15–20 min before HS collection. The duration of each collection exceeded 5 min, with a randomly selected 10-s segment of the highest quality signal for each subject.

Table 1. Description of HFpEF heart sound dataset.

Table 2. Description of PhysioNet/CinC 2016 dataset.
4.2 Signal preprocessing
First, PCG signals were filtered in the 10–1,000 Hz range with a Butterworth filter to eliminate low-frequency noise and baseline wandering, and then, a fourth-order adaptive FIR notch filter was utilized to eliminate 50 Hz interference. High-frequency noise from artifacts including muscle contractions, electrode movement, friction between the sensor and the skin, respiratory noise or environmental noise were further denoised using the multilevel singular value decomposition and adaptive threshold wavelet transform. Subsequently, each signal was downsampled to 2205 Hz, followed by Z-score normalization.
4.3 PCG signal to image conversion
To extract texture and deep features, this study employed gammatone filters to generate 2D time-frequency gammatonegrams from the PCG signals. These filters effectively replicate human auditory perception characteristics, providing a comprehensive and robust time-frequency representation of the signal. In gammatonegrams, lower frequencies have narrower bandwidths, while higher frequencies have broader ones, in contrast to the STFT spectrogram, which employs a constant bandwidth across the entire frequency range (Gupta et al., 2021). The impulse response of a gammatone filter is derived from the product of a Gamma function and a sinusoidal tone using Equation 1:
where fc denotes the filter’s central frequency, t is the time, φ corresponds to the carrier phase and n specifies the filter order. The parameters a and b define the gammatone filter’s amplitude and bandwidth, respectively. By stacking the responses of each frame across overlapping time frames, the gammatonegram spectrogram is ultimately formed using the entire Gammatone filter bank.
4.4 Texture feature extraction
Texture analysis was employed to quantify spatial relationships between image voxels in the PCG gammatonegram. A set of classical texture matrices was computed to capture multi-dimensional signal patterns, including the Gray Level Co-occurrence Matrix (GLCM), Gray Level Run Length Matrix (GLRLM), Gray Level Size Zone Matrix (GLSZM), and Gray Level Dependence Matrix (GLDM). All texture features were extracted in accordance with the Image Biomarker Standardization Initiative (IBSI) guidelines, and the mathematical formulations of these matrices are summarized below. Pyradiomics (https://github.com/AIM-Harvard/pyradiomics) was used to extract a total of 70 texture features in this study (Castellano et al., 2004; Van Griethuysen et al., 2017), Specific feature descriptions are provided in Supplementary Material.
The GLCM quantifies the joint occurrence of two gray levels separated by a fixed spatial displacement Δx,Δy in direction α. Formally, the matrix element PGLCMgi,gj is defined as Equation 2:
The matrix is normalized by Equation 3:
where Ix,y is the gray level of pixel x,y; g, gi, and gj denote gray-level intensity values. Specifically, g represents a generic gray level in the image, whereas gi and gj correspond to the pair of gray levels whose spatial or structural relationships are quantified by a given texture matrix. These gray-level values are derived from the discretized PCG gammatonegram and are used consistently across all matrix definitions.
GLRLM captures the length of consecutive pixels (runs) with identical gray level g along direction α. A run of length r is defined as a maximal sequence of pixels using Equation 4:
where the sequence is terminated when the condition no longer holds. The GLRLM is defined as Equation 5:
GLSZM characterizes the size distribution of homogeneous connected regions (zones) independent of direction. A zone is defined as an 8-connected set of pixels with identical gray level g. The GLSZM entry PGLSZMg,s counts using Equation 6:
where s denotes the number of pixels in the zone.
GLDM quantifies the number of neighboring pixels within direction α whose gray-level difference from the reference pixel does not exceed a tolerance δ. The dependence count is defined as Equation 7:
The GLDM element PGLDMg,d is therefore expressed as Equation 8:
where Nα is the neighborhood defined along direction α, δ is the gray-level tolerance threshold. The inner summation computes the dependence count, i.e., the number of neighboring pixels whose gray-level difference from the reference pixel is ≤ δ. PGLDMg,d counts the number of pixels with gray level g and dependence value d. “#” denotes the cardinality operator, representing the number of pixels satisfying the given condition. The symbol “∧” denotes the logical AND operator, indicating that both conditions must be simultaneously satisfied. I· denotes the indicator function, which takes the value 1 when the condition is true and 0 otherwise.
4.5 Transfer learning
Convolutional neural networks (CNNs), which consist of multiple convolutional layers, excel at capturing spatial or local patterns within images. By utilizing multi-scale filters of varying kernel sizes, they generate diverse high-level representations. To address the challenge of limited dataset size often associated with CNNs, transfer learning can be employed. This approach leverages pre-trained CNNs for deep feature extraction. The PCG gammatonegram spectrogram is subsequently resized for input into the pre-trained CNN model. Previous studies have indicated that some modules such as inception modules, residual networks, and skip connections can enhance model performance. Consequently, this study utilizes three deep transfer learning architectures as feature extractors, namely ResNet50 (He et al., 2016), DenseNet121 (Huang et al., 2017), and InceptionResNetV2 (Szegedy et al., 2017). The Adam optimizer is employed for model fine-tuning, while early stopping is used as a regularization technique to prevent overfitting.
4.5.1 ResNet50
ResNet50 follows the CNN architecture but with a specific variant of the ResNet architecture (He et al., 2016), which used residual learning to address the vanishing gradient. Each layer in a ResNet comprises multiple blocks. The 50-layer ResNet uses a bottleneck architecture in its building blocks, incorporating 1 × 1 convolutions to reduce parameters and matrix multiplications. This approach, which stacks three layers rather than two, accelerates training for each layer.
4.5.2 DenseNet121
DenseNet is a CNN architecture known for its unique cross-layer connectivity pattern. It establishes direct connections between each layer and all subsequent layers (Huang et al., 2017). This connectivity pattern promotes information flow by allowing gradients to be shared across layers during backpropagation, thereby addressing the vanishing gradient issue.
4.5.3 InceptionResNetV2
InceptionResNetV2 architecture is built upon inception blocks, incorporating operations that utilize multiple convolutional filter sizes simultaneously for feature extraction (Szegedy et al., 2017). Bottleneck layers are designed to develop the cross-channel correlations between different paths for reduce computational costs. The architecture combines the advantages of residual networks with the design of inception modules, allowing the model to effectively capture diverse patterns.
4.6 Heterogeneous stacking ensemble learning
Traditional ensemble learning methods predominantly depend on averaging and majority voting, neglecting the impact of less effective learners (Polikar, 2012). To address this limitation and achieve more robust results, an ensemble of deep CNNs can be employed, leveraging the combined decisions of multiple models (Islam and Zhang, 2018). Specifically, this study proposes a heterogeneous stacking ensemble learning model.
4.6.1 Heterogeneous base learner construction
To enhance detection accuracy and reduce the errors, it is commonly acknowledged that the diversity of the base learners plays a crucial role in building a high-quality ensemble model (Finn et al., 2017). Therefore, in the selection of base learners, we adopted three various independently pre-trained transfer learning models and one texture analysis model to generate optimal results by integrating multiple classifiers with minimal errors. The transfer learning models leverage pre-trained CNNs to extract deep features, which are then reduced in dimensionality using PCA and fed into a random forest classifier, while the texture analysis model extracts texture features and inputs them into an SVM with recursive feature elimination. Next, we use the outputs of these four distinct classification models as the input for the meta-learner and propose a weighted AUC-based integration mechanism for ensemble learning.
4.6.2 Base learner integration and stacking ensemble classifier
By integrating the outputs of the base learners, a heterogeneous stacking ensemble model was proposed using a weighted AUC-based integration mechanism. The framework incorporates predictions from four distinct base learners, including a texture analysis-based SVM model and three transfer learning-based random forest (RF) models. Ensemble classification enables effective training of the meta learner on a limited number of samples while reducing the risk of overfitting, by leveraging the class posterior probabilities generated by the four base models. Next, we provide a detailed description of the proposed ensemble strategy. Unlike conventional stacking methods that treat all base learners equally, our approach introduces a weighted integration mechanism based on the AUC performance of each base model. Specifically, the class posterior probabilities output by each base learner are first calibrated and then weighted according to their validation AUC scores, allowing models with stronger discriminative power to contribute more significantly to the final decision. These weighted outputs are concatenated and used as the input for the meta learner, which is trained to learn the optimal decision boundaries by capturing high-level interactions among the base learners. This design enhances the robustness and generalizability of the ensemble, particularly in scenarios with limited training data.
Let the posterior probability Pμ∈0,1 of a base learner Lμyxi, where xi∈RN and y∈−1,+1 indicates the ith input and output patterns. Lμ−1xi and Lμ+1xi respectively represents the forecasted outputs of the μth base learner for class −1 and class +1, where Lμ−1xi+Lμ+1xi=1. Next, a detailed description of the weighted-based heterogeneous stacking ensemble mechanism was presented. The ith element ζ of the input vector for the meta learner can be expressed as Equation 9
where μ is the number of base learners, ωi is the weight of the ith base learner. Since an AUC value evaluates overall classifier performance and reflects generalizability, it is well-suited as a weight for assigning to the corresponding base learners. Let ℏi denotes the AUC of the ith base learner, ωi can be calculated by Equation 10
Since this study ultimately includes one texture analysis model and three transfer learning models as base learners, μ is set to 4. The posterior probabilities of each base learner that was incorporated by the corresponding weight have been used as input to the meta learner. A multilayer perceptron composed of three hidden layers, with 256, 128, and 64 neurons in each layer respectively, has been utilized as the meta learner. Finally, through stacking ensemble learning, outputs from the four classifiers are fused to determine the ultimate classification result.
4.7 Bayesian optimization
This framework involves numerous weights and hyperparameters, such as batch size and learning rate, which need to be determined and optimized individually. This study applied Bayesian optimization to hyperparameter tuning (Frazier, 2018). Bayesian optimization utilizes prior observations of a loss function l to determine the optimal sampling point. It assumes that the loss function l follows a Gaussian process, which provides an analytically tractable posterior distribution over the loss function l. This setup enables updates to the loss function lη^ as new losses are computed for additional hyperparameter sets η^. The algorithm flow of Bayesian optimization can be summarized as follows:
1. Given observed values of lη, update the posterior expectation of l using the Gaussian process model.
2. Find new η^ that maximizes
3. Compute the loss function for lη^.
All relevant parameters for each ensemble or baseline classification model were optimized, and each weak learner within the ensemble models was independently tuned in each fold. This approach facilitates the comprehensive testing and training of model on the entire dataset, providing a more generalized and more impartial assessment of model performance compared to a simple training and testing set separation.
5 Experiments
The public PhysioNet/CinC 2016 database was used to evaluate the model’s baseline performance, while the heart failure PCG dataset was used to assess the model’s ability to distinguish heart failure. Each dataset was split into a training set and an independent testing set with a 7:3 ratio using stratified sampling, ensuring that heart sound segments from the same subject appeared only in either the training or the testing set. Five-fold cross-validation was used on the training set for model development, while model performance was evaluated on the testing set. The data splitting was repeated 10 times with different partitions, and the experiments were repeated 10 times; the average results were taken as the final model performance. In stacking ensemble learning, after splitting the dataset into training and testing sets, the base learners are trained using K-fold cross-validation on the training set. For each fold, base learners are trained on K-1 folds and generate predictions on the held-out fold, creating out-of-fold predictions for the entire training set, and then these out-of-fold predictions serve as input features to train the meta learner, as shown in Figure 1B. After training, base learners are applied to testing set for producing base learner predictions, and finally the meta learner uses these base learner predictions as input to generate the final predictions on the testing set. Bayesian optimization (Figure 1C) was applied to tune the hyperparameters, and the final experimental parameter settings are shown in the Table 3. To assess whether the predictive performance differed significantly between models, pairwise comparisons of AUCs were conducted using the nonparametric DeLong test, which provides a distribution-free estimate of the variance and covariance of correlated ROC curves.

Figure 1. (A) Flow chart of this study. yii=1,2,3,4 Denotes the outputs of the base learners, while yi′i=1,2,3,4 represents the inputs to the meta-learner after heterogeneous stacking ensemble. (B) Illustrates the training and test pipeline. (C) Presents the Bayesian optimization pipeline.

Table 3. Experimental parameter settings.
6 Results
6.1 Texture analysis construction
Table 4 presents the performance of different machine learning models used as base learners for HFpEF diagnosis. It can be seen that k-Nearest Neighbor (KNN) and logistic regression (LR) achieved relatively poor classification performance, while RF and SVM using texture features significantly outperformed KNN and LR in identifying HFpEF. Moreover, SVM outperformed RF in terms of AUC, accuracy, specificity, and F1 score, achieving 0.835, 0.829, 0.931, and 0.839 on the testing set, respectively. Therefore, through comparison, the texture analysis-based SVM-RFE is selected as the first base classifier.

Table 4. The classification performance of different classifiers using texture features on HF dataset.
6.2 Construction and selection of base learners
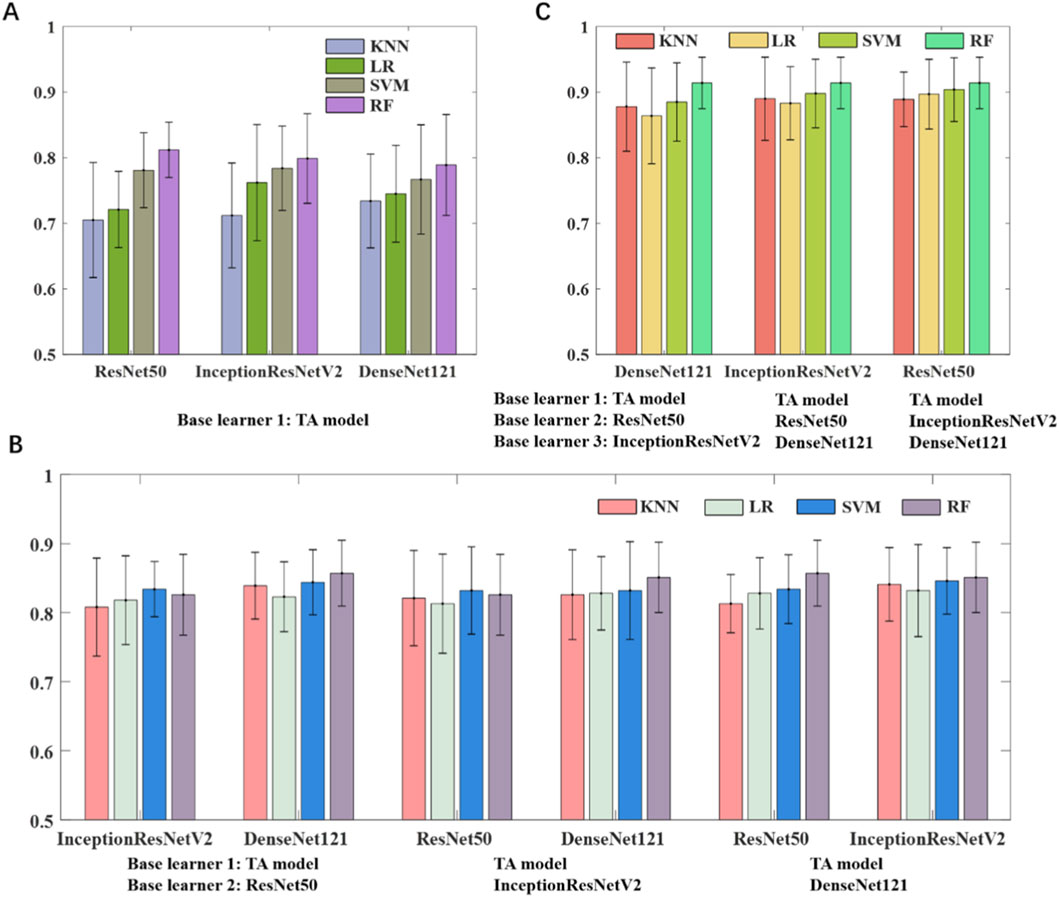
In this study, we developed two categories of base learners: one based on texture analysis and the other leveraging transfer learning. The machine learning classifiers and the number of base learners used in the ensemble were determined through different combination strategies. We first adopted a stacking strategy in which a two-layer MLP (256 neurons per layer) was used to fuse the outputs of the base classifiers. As shown in Figure 2A, combining two base learners, namely an SVM-based texture model and an RF-based transfer learning model, outperformed either individual model and achieved an AUC of 0.812 on the testing set. Increasing the number of base learners to three (Figure 2B) by integrating the texture model with two RF-based transfer learning models, the AUC of the model improved to 0.857. As shown in Figure 2C, the best performance was obtained when one texture model and three transfer learning models were combined, yielding an AUC of 0.914. Through stacking ensemble learning, the outputs of all four base classifiers were effectively fused to generate the final prediction.

Figure 2. Model performance of ensemble learning models using different base learners. (A) Texture analysis model and one transfer learning model. (B) Texture analysis model and two transfer learning models. (C) Texture analysis model and three transfer learning models.
6.3 Meta learner construction
This study developed four base classifiers, which are an RFE-SVM based on texture analysis of PCG spectrogram, and three PCA-RFs based on deep features from ResNet50, InceptionResNetV2 and DenseNet121, respectively. After determining the number and type of base learners, we compared the impact of using LR and MLP as meta learners on the performance of the ensemble model. The ensemble strategy was consistent with the previous section. As shown in Table 5, the classification performance of the MLP as a meta learner was superior to that of LR. Furthermore, we evaluated how different hidden-layer configurations influence the performance of the MLP meta-learner. As shown in Figure 3, a two-layer MLP with 256 and 128 neurons achieved an AUC of 0.914 and an accuracy of 0.833. Adding a third hidden layer further improved overall performance, with the best results obtained when the additional layer contained 64 neurons (AUC = 0.933, accuracy = 0.902). However, deeper architectures led to performance degradation. Accordingly, the final meta-learner was configured as a three-layer MLP with 256, 128, and 64 neurons.

Table 5. The classification performance of different meta learners.

Figure 3. The impact of the number of hidden layers and neurons per layer on the performance of the ensemble model for the meta learner. (A–C) The relationships between the model’s AUC and the number of neurons with two, three and four hidden layers. (D–F) The relationships between the model’s accuracy and the number of neurons with two, three and four hidden layers.
6.4 Comparison of ensemble strategies
To assess the effectiveness of our proposed ensemble strategy, we compared it with two alternative integration methods: voting and stacking. Table 6 presents the performance of classification models employing various integration strategies on the training and testing sets. The result reveal that the performance of ensemble learning models based on stacking and voting are relatively similar in terms of specificity, but the stacking-based ensemble learning model is superior, achieving an AUC of 0.914, an accuracy of 0.872, a sensitivity of 0.915, a specificity of 0.843, a precision of 0.859, and an F1 score of 0.892. The voting-based ensemble learning model achieves the worst performance on those indicators. Furthermore, the heterogeneous stacking-based ensemble learning model proposed in this study achieves the highest classification performance across all metrics, with an AUC, accuracy, sensitivity, specificity, precision, and F1 score of 0.933, 0.902, 0.958, 0.843, 0.968, and 0.923, respectively. The ROC curves of the three ensemble models are shown in the Figure 4.

Table 6. Performance comparison of ensemble models based on different integration strategies on training and testing sets.

Figure 4. ROC curves of ensemble models based on different fusion strategies. (A) Training set. (B) Testing set.
6.5 Ablation study
To evaluate the contribution of each component in the proposed heterogeneous ensemble architecture, we conducted a series of ablation experiments by removing (i) the meta-learner, and (ii) individual CNN feature extractors (ResNet50, DenseNet, and InceptionResNetV2). The results are summarized in Table 7. Removing the MLP meta-learner produced the largest performance drop, demonstrating its essential role in integrating heterogeneous radiomic and deep feature representations. Removing DenseNet led to the greatest degradation among CNN branches, indicating its strong complementary contribution to the spectral encoding of HFpEF-related PCG patterns. Models trained with CNN-only features showed substantially lower performance, confirming the necessity of feature fusion. The full model achieved the best overall performance. These results collectively validate the robustness and design rationale of the proposed ensemble system.

Table 7. Results of the ablation studies.
6.6 Model comparison
To benchmark our approach against widely used CNN architectures, we evaluated six representative models, such as ResNet50, DenseNet, InceptionResNetV2, MobileNet, ShuffleNet V2, and GhostNe, on both the public PhysioNet/CinC 2016 database and our private clinical heart failure dataset. As summarized in Table 8, the proposed method consistently outperformed all baseline CNN models across both datasets, demonstrating superior discriminative capability.

Table 8. Performance comparison of the proposed heterogeneous stacking ensemble learning model with deep learning approaches on the testing set.
7 Discussion
This study proposed a heterogeneous stacking ensemble learning model that integrates texture analysis and transfer learning for the diagnosis of HFpEF. To the best of our knowledge, this is the first study to utilize texture analysis for feature extraction from heart sounds and to explore the diagnosis of HFpEF using an ensemble learning framework based on PCG signals. Texture features capture detailed relational patterns within the PCG spectrogram, whereas deep representations extracted via transfer learning provide more abstract and complementary information. Comprising an RFE-SVM texture model and three PCA-RF transfer learning models, effectively combines the strengths of heterogeneous base learners to enhance diagnostic performance.
The treatment plans for HFpEF and HFrEF are completely different (Redfield et al., 2023). Thus, the findings of this study hold substantial value in aiding the auxiliary diagnosis of HFpEF and supporting clinicians in patient management. PCG are a direct reflection of the mechanical activity of the heart. HFpEF primarily results from reduced myocardial compliance and impaired diastolic function, both of which are indicative of declining cardiac mechanics. Consequently, PCG deep feature representation and feature fusion could potentially offer enhanced diagnostic capabilities for HFpEF. The advantage of texture analysis in this context is highlighted by its ability to extract detailed patterns and features from PCG gammatonegrams, which can enhance the accuracy and robustness of diagnostic models. GLCM contrast/entropy reflects increased cycle-to-cycle variability in high-frequency components, which is consistent with impaired relaxation and altered filling dynamics in HFpEF. GLRLM short-run features capture transient acoustic irregularities associated with stiff ventricular walls and abnormal diastolic sound patterns. GLDM dependence entropy characterizes localized complexity in the gammatonegram, which increases in HFpEF due to disrupted ventricular suction and elevated filling pressures.
PCG classification is a key component of intelligent auscultation and supports the diagnosis and risk assessment of cardiovascular diseases. Table 9 summarizes representative studies that employ hybrid ensemble frameworks and deep learning models for heart sound analysis. Most approaches focus on improving classification performance through model ensembling (She and Cheng, 2022). Noman et al. (2019) proposed a deep CNN framework combining 1D and 2D CNNs into a time–frequency ensemble. Chen et al. (2022) evaluated multi-resolution models and incorporated ensemble learning to boost accuracy. Potes et al. (2016) extracted statistical and wavelet-based features for an AdaBoost classifier, trained CNNs on frequency-band–decomposed PCG cycles, and fused both outputs. Baydoun et al. (2020) used statistical and wavelet features with bagging and boosting to enhance ensemble performance. Singh et al. (2024) introduced a transfer learning–based ensemble using spectrogram images and STFT features to improve robustness and accuracy. To our knowledge, this is the first study to integrate handcrafted texture features with transfer learning–derived deep features from PCG gammatonegrams within an ensemble learning framework for HFpEF diagnosis. The results demonstrate that combining texture and deep representations yields superior performance and effectively improves HFpEF discrimination.

Table 9. The summary of ensemble learning for heart sound classification during recent years.
In the field of medical artificial intelligence research, more and more studies are focusing on the computer-aided diagnosis of HFpEF using advanced supervised algorithms. Table 10 provides an overview of several related studies previously published about the computer-aided diagnosis of HFpEF using medical data and information. Because these studies used different datasets, patient populations, acquisition conditions, and outcome definitions, the results are not directly comparable to the present work. This table is intended only to provide general context regarding prior methods rather than a head-to-head performance comparison. The clinical decision system demonstrated high diagnostic accuracy for heart failure, achieving a 98.3% concordance rate with specialists in a retrospective test dataset and 98% in a prospective pilot study. These findings suggest that AI-CDSS could significantly aid in heart failure diagnosis, especially in the absence of heart failure specialists (Choi et al., 2020). Kwon et al. (2021) developed and validated a deep learning model by using electrocardiography (ECG), showing high performance in detecting HFpEF. The model’s performance indicates that conventional and diverse life-type ECG devices can effectively screen for HFpEF and help prevent disease progression. Ward et al. (2022) developed a machine learning-based ensemble model that demonstrated strong diagnostic performance for HFpEF using demographic and plasma biomarker data, offering a promising noninvasive diagnostic tool and identifying key biomarkers for further study. Akerman et al. (2023) used 3D CNNs to analyze single apical 4-chamber transthoracic echocardiogram video clips for detecting HFpEF. The model showed excellent performance in distinguishing HFpEF from non-HFpEF, outperforming traditional clinical scores and identifying patients who have increased mortality rates. Wu et al. (2024) investigated the use of natural language processing to enhance the detection and diagnosis of HFpEF through electronic health records (EHR).

Table 10. The summary of artificial intelligence in the diagnosis of HFpEF during recent years.
Most existing studies rely on multimodal fusion of large-scale health data, typically integrating clinical information, laboratory indicators, and features from electrocardiograms or echocardiograms. In contrast, our study takes an alternative approach by focusing exclusively on PCG signals. By extracting physiological and pathological information directly related to the mechanical activity of the heart, the proposed method aims to facilitate non-invasive detection of HFpEF. Despite a relatively small sample size, comparable classification performance was achieved through high-dimensional texture and deep feature extraction from PCG spectrograms combined with a heterogeneous ensemble learning model. These findings highlight the diagnostic potential of heart sounds for HFpEF.
This study also has several limitations. First, the HFpEF database used in this study is limited by a single-center cross-sectional design with a small sample size. Second, the focus of the study is primarily on diagnostic accuracy, with insufficient exploration of the model’s long-term clinical implications, such as its impact on patient outcomes. Future research should include longitudinal studies to evaluate how this diagnostic tool affects clinical outcomes. Third, the exclusion of patients with atrial fibrillation restricts the applicability of our findings to the broader HFpEF population. To enhance the model’s generalizability, larger datasets and external validation from multiple institutions are needed.
8 Conclusion
This study explored the application and utility of PCG-based ensemble learning in identifying HFpEF. Firstly, the Gammatone filter was applied to PCG signals for two-dimensional spectrogram transform, followed by feature extraction using texture analysis and transform learning by the pre-trained ResNet50, InceptionResNetV2, and DenseNet121. Texture features were selected via RFE and used to construct an SVM classifier, while deep features were reduced by PCA and modeled using RF classifiers. An MLP meta-learner was then employed to integrate all base classifiers within a heterogeneous stacking framework. The results demonstrate that the proposed ensemble strategy can effectively detect HFpEF from heart sounds, highlighting its potential value for clinical screening and decision support.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by The First Affiliated Hospital of Chongqing Medical University. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. The manuscript presents research on animals that do not require ethical approval for their study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
YZ: Conceptualization, Funding acquisition, Methodology, Project administration, Writing – original draft, Writing – review and editing. JQ: Resources, Supervision, Validation, Visualization, Writing – review and editing. FL: Conceptualization, Data curation, Formal Analysis, Resources, Writing – review and editing. XL: Resources, Supervision, Validation, Writing – review and editing. XG: Conceptualization, Formal Analysis, Funding acquisition, Project administration, Resources, Writing – original draft, Writing – review and editing.
Funding
The author(s) declared that financial support was received for this work and/or its publication. This study was supported by the National Natural Science Foundation of China (No. 31800823 and 31870980), the Natural Science Foundation of Chongqing (CSTB2023NSCQ-MSX0089 and cstc2021jcyj-msxmX0192), Joint project of Chongqing Health Commission and Science and Technology Bureau (2025QNXM003), and project supported by Scientific and Technological Research Program of Chongqing Municipal Education Commission (Grant No. KJQN202500480).
Conflict of interest
The author(s) declared that this work was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declared that generative AI was not used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2025.1694781/full#supplementary-material
References
Akerman A. P., Porumb M., Scott C. G., Beqiri A., Chartsias A., Ryu A. J., et al. (2023). Automated echocardiographic detection of heart failure with preserved ejection fraction using artificial intelligence. JACC Adv. 2 (6), 100452. doi:10.1016/j.jacadv.2023.100452
Bao X., Xu Y., Lam H.-K., Trabelsi M., Chihi I., Sidhom L., et al. (2023). Time-frequency distributions of heart sound signals: a comparative study using convolutional neural networks. Biomed. Eng. Adv. 5, 100093. doi:10.1016/j.bea.2023.100093
Baydoun M., Safatly L., Ghaziri H., El Hajj A. (2020). Analysis of heart sound anomalies using ensemble learning. Biomed. Signal Process. Control 62, 102019. doi:10.1016/j.bspc.2020.102019
Borlaug B. A., Paulus W. J. (2011). Heart failure with preserved ejection fraction: pathophysiology, diagnosis, and treatment. Eur. Heart Journal 32 (6), 670–679. doi:10.1093/eurheartj/ehq426
Cao M., Gardner R. S., Hariharan R., Nair D. G., Schulze C., An Q., et al. (2020). Ambulatory monitoring of heart sounds via an implanted device is superior to auscultation for prediction of heart failure events. J. Cardiac Failure 26 (2), 151–159. doi:10.1016/j.cardfail.2019.10.006
Chen H., Chhor M., Rayner B. S., McGrath K., McClements L. (2021). Evaluation of the diagnostic accuracy of current biomarkers in heart failure with preserved ejection fraction: a systematic review and meta-analysis. Archives Cardiovasc. Dis. 114 (12), 793–804. doi:10.1016/j.acvd.2021.10.007
Chen J., Dang X., Li M. (2022). “Heart sound classification method based on ensemble learning,” in 2022 7th international conference on intelligent computing and signal processing (ICSP) (IEEE), 8–13.
Drazner M. H., Rame J. E., Dries D. L. (2003). Third heart sound and elevated jugular venous pressure as markers of the subsequent development of heart failure in patients with asymptomatic left ventricular dysfunction. Am. Journal Medicine 114 (6), 431–437. doi:10.1016/s0002-9343(03)00058-5
Fakhry M., Gallardo-Antolín A. (2024). Elastic net regularization and gabor dictionary for classification of heart sound signals using deep learning. Eng. Appl. Artif. Intell. 127, 107406. doi:10.1016/j.engappai.2023.107406
Finn C., Abbeel P., Levine S. (2017). “Model-agnostic meta-learning for fast adaptation of deep networks,” in Proceedings of Machine Learning Research (Cambridge, MA: PMLR), 1126–1135.
Frazier P. I. (2018). “Bayesian optimization,” in Recent advances in optimization and modeling of contemporary problems (Catonsville, MD: Informs), 255–278. doi:10.1287/educ.2018.0188
Ghosh S. K., Ponnalagu R., Tripathy R. K., Panda G., Pachori R. B. (2022). Automated heart sound activity detection from PCG signal using time–frequency-domain deep neural network. IEEE Trans. Instrum. Meas. 71, 1–10. doi:10.1109/tim.2022.3192257
Gjoreski M., Gradišek A., Budna B., Gams M., Poglajen G. (2020). Machine learning and end-to-end deep learning for the detection of chronic heart failure from heart sounds. Ieee Access 8, 20313–20324. doi:10.1109/access.2020.2968900
Gupta S., Agrawal M., Deepak D. (2021). Gammatonegram based triple classification of lung sounds using deep convolutional neural network with transfer learning. Biomed. Signal Process. Control 70, 102947. doi:10.1016/j.bspc.2021.102947
He K., Zhang X., Ren S., Sun J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
Huang G., Liu Z., Van Der Maaten L., Weinberger K. Q. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708.
Islam J., Zhang Y. (2018). Brain MRI analysis for Alzheimer’s disease diagnosis using an ensemble system of deep convolutional neural networks. Brain Informatics 5, 1–14. doi:10.1186/s40708-018-0080-3
Khan F. A., Abid A., Khan M. S. (2020). Automatic heart sound classification from segmented/unsegmented phonocardiogram signals using time and frequency features. Physiol. Measurement 41 (5), 055006. doi:10.1088/1361-6579/ab8770
Khan K. N., Khan F. A., Abid A., Olmez T., Dokur Z., Khandakar A., et al. (2021). Deep learning based classification of unsegmented phonocardiogram spectrograms leveraging transfer learning. Physiol. Measurement 42 (9), 095003. doi:10.1088/1361-6579/ac1d59
Kwon J.-m., Kim K.-H., Eisen H. J., Cho Y., Jeon K.-H., Lee S. Y., et al. (2021). Artificial intelligence assessment for early detection of heart failure with preserved ejection fraction based on electrocardiographic features. Eur. Heart Journal-Digital Health 2 (1), 106–116. doi:10.1093/ehjdh/ztaa015
Luo H., Weerts J., Bekkers A., Achten A., Lievens S., Smeets K., et al. (2023). Association between phonocardiography and echocardiography in heart failure patients with preserved ejection fraction. Eur. Heart Journal-Digital Health 4 (1), 4–11. doi:10.1093/ehjdh/ztac073
Noman F., Ting C.-M., Salleh S.-H., Ombao H. (2019). “Short-segment heart sound classification using an ensemble of deep convolutional neural networks,” in ICASSP 2019-2019 IEEE international conference on acoustics, speech and signal processing (ICASSP) (IEEE), 1318–1322.
Polikar R. (2012). “Ensemble learning,” in Ensemble machine learning: methods and applications, 1–34.
Potes C., Parvaneh S., Rahman A., Conroy B. (2016). “Ensemble of feature-based and deep learning-based classifiers for detection of abnormal heart sounds,” in 2016 computing in cardiology conference (CinC) (IEEE), 621–624.
Reddy Y. N., Carter R. E., Obokata M., Redfield M. M., Borlaug B. A. (2018). A simple, evidence-based approach to help guide diagnosis of heart failure with preserved ejection fraction. Circulation 138 (9), 861–870. doi:10.1161/CIRCULATIONAHA.118.034646
Ren Z., Qian K., Dong F., Dai Z., Nejdl W., Yamamoto Y., et al. (2022). Deep attention-based neural networks for explainable heart sound classification. Mach. Learn. Appl. 9, 100322. doi:10.1016/j.mlwa.2022.100322
She C.-J., Cheng X.-F. (2022). Design framework of hybrid ensemble identification network and its application in heart sound analysis. AIP Adv. 12 (4), 045117. doi:10.1063/5.0083764
Singh S. A., Devi N. D., Singh K. N., Thongam K., Majumder S. (2024). An ensemble-based transfer learning model for predicting the imbalance heart sound signal using spectrogram images. Multimedia Tools Appl. 83 (13), 39923–39942. doi:10.1007/s11042-023-17186-9
Szegedy C., Ioffe S., Vanhoucke V., Alemi A. (2017). “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Proceedings of the AAAI conference on artificial intelligence, 2017.
Tang H., Li T., Park Y., Qiu T. (2010). Separation of heart sound signal from noise in joint cycle frequency–time–frequency domains based on fuzzy detection. IEEE Trans. Biomed. Eng. 57 (10), 2438–2447. doi:10.1109/TBME.2010.2051225
Thakur P. H., An Q., Swanson L., Zhang Y., Gardner R. S. (2017). Haemodynamic monitoring of cardiac status using heart sounds from an implanted cardiac device. Esc. Heart Failure 4 (4), 605–613. doi:10.1002/ehf2.12171
Van Griethuysen J. J., Fedorov A., Parmar C., Hosny A., Aucoin N., Narayan V., et al. (2017). Computational radiomics system to decode the radiographic phenotype. Cancer Research 77 (21), e104–e107. doi:10.1158/0008-5472.CAN-17-0339
Ward M., Yeganegi A., Baicu C. F., Bradshaw A. D., Spinale F. G., Zile M. R., et al. (2022). Ensemble machine learning model identifies patients with HFpEF from matrix-related plasma biomarkers. Am. J. Physiology-Heart Circulatory Physiology 322 (5), H798–H805. doi:10.1152/ajpheart.00497.2021
Wu J., Biswas D., Ryan M., Bernstein B. S., Rizvi M., Fairhurst N., et al. (2024). Artificial intelligence methods for improved detection of undiagnosed heart failure with preserved ejection fraction. Eur. J. Heart Fail. 26 (2), 302–310. doi:10.1002/ejhf.3115
Xiao B., Xu Y., Bi X., Zhang J., Ma X. (2020). Heart sounds classification using a novel 1-D convolutional neural network with extremely low parameter consumption. Neurocomputing 392, 153–159. doi:10.1016/j.neucom.2018.09.101
Zeng W., Yuan J., Yuan C., Wang Q., Liu F., Wang Y. (2021). A new approach for the detection of abnormal heart sound signals using TQWT, VMD and neural networks. Artif. Intell. Rev. 54 (3), 1613–1647. doi:10.1007/s10462-020-09875-w
Zheng Y., Guo X., Qin J., Xiao S. (2015). Computer-assisted diagnosis for chronic heart failure by the analysis of their cardiac reserve and heart sound characteristics. Comput. Methods Programs Biomedicine 122 (3), 372–383. doi:10.1016/j.cmpb.2015.09.001
Zheng Y., Guo X., Wang Y., Qin J., Lv F. (2022). A multi-scale and multi-domain heart sound feature-based machine learning model for ACC/AHA heart failure stage classification. Physiol. Meas. 43 (6), 065002. doi:10.1088/1361-6579/ac6d40
Zheng Y., Guo X., Yang Y., Wang H., Liao K., Qin J. (2023). Phonocardiogram transfer learning-based CatBoost model for diastolic dysfunction identification using multiple domain-specific deep feature fusion. Comput. Biol. Med. 156, 106707. doi:10.1016/j.compbiomed.2023.106707